语言是人与人沟通交流的重要工具,是信息传递的重要载体,不同类别的语言系统有其专门的词汇、语法和框架结构,用来传递复杂的语义信息。
不过,你知道吗,科学界也有属于自己的“语言”!科学语言是用于表述科学知识的一种特定语言。近年来,在物质科学、信息科学、生命科学等领域,独特的科学语言正闪烁着耀眼的魅力,为不同学科的交叉合作搭建沟通的桥梁。
如何加速科学新发现?我院 AI 交叉中心团队提出了新的想法!他们利用科学语言大模型来表征纷繁复杂的科学知识,用人工智能加速科学新知识的发现。
近日,团队组织撰写了一本关于科学语言的“新华字典”——《科学语言大模型:生物和化学领域综述》,从生命科学和物质科学等视角,围绕生物和化学两个领域全面回顾和梳理了科学语言大模型(Sci-LLMs)的最新进展,着重分析了针对文本科学知识、小分子化合物、大分子蛋白质、基蛋白质大语言模型因组序列以及多模态科学数据的 LLMs,共计75页,引用了300余篇参考文献。

我们为什么要做这件事?
近年来,大型语言模型(LLMs)已成为推动自然语言理解能力变革的关键力量,标志着人工智能通用性方面的重大突破。LLMs 的应用已超越传统自然语言的范畴,覆盖了各类科学学科中开发的专用科学语言系统,从而推动了科学语言大模型(Sci-LLMs)的诞生。然而,目前关于 Sci-LLMs 的进展调查尚属不足,这让很多领域内的科研人员犯了难。
团队从生物化学领域研究方向出发,全面总结了文本科学大语言模型、分子大语言模型、蛋白质大语言模型、基因组大语言模型、多模态科学大语言模型五个具体研究主题,并从模型、数据集、评估、总结四个方面展开描述,为更多科研人员在科学人工智能领域的崭新方向探索未知指引方向。
文本科学大语言模型
文本科学大语言模型(Text-Sci-LLM)是专门针对大量文本科学数据进行训练的大语言模型,擅长理解、生成书面形式的人类语言并与之互动。研究采用了 KnowEval 评估方法,根据科学知识的复杂程度进行分类,考察模型在基础知识,专业知识和创新知识方面的能力。
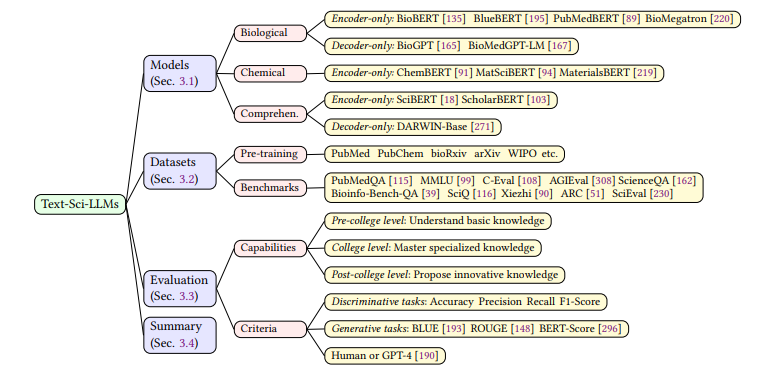
分子大语言模型
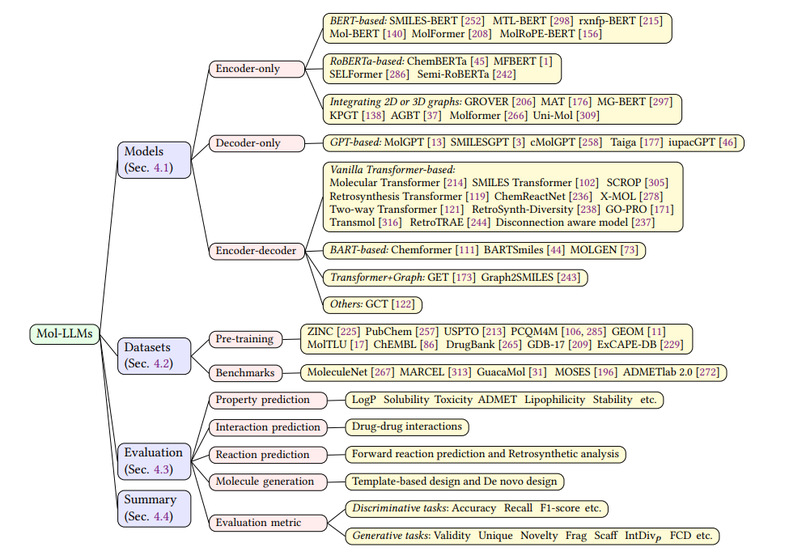
分子大语言模型是根据分子数据训练的专业大语言模型,可以理解和预测分子的化学性质和行为。研究列举了诸多基于不同架构的分子语言模型,重点关注这些模型如何解释和处理化学语言,此外还通过分子性质预测、相互作用预测、反应预测和分子生成对模型进行评估。它是药物发现、材料科学和理解复杂化学相互作用的宝贵工具,具有重要的意义。
蛋白质大语言模型
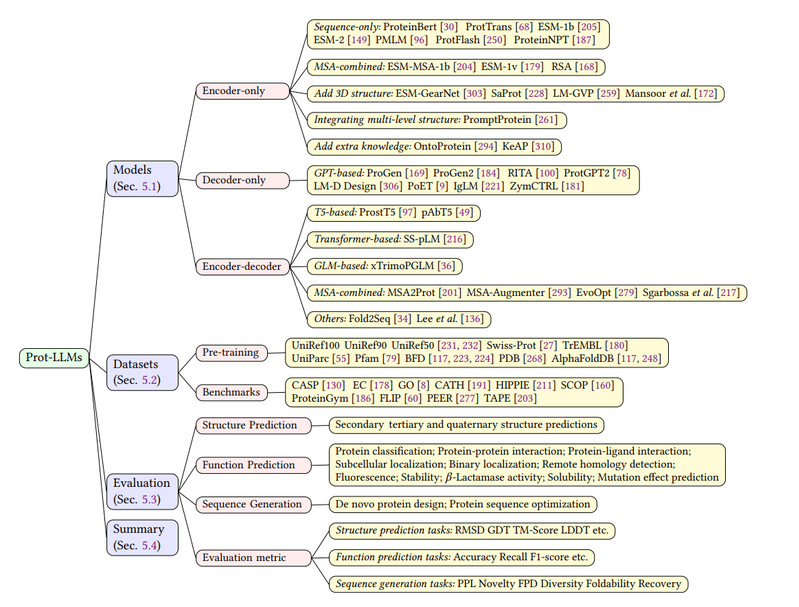
蛋白质大语言模型专门针对蛋白质相关数据进行训练,包括氨基酸序列、蛋白质折叠模式以及蛋白质相关的其他生物数据。因此,它们具有准确预测蛋白质结构、功能和相互作用的能力。
基因组大语言模型
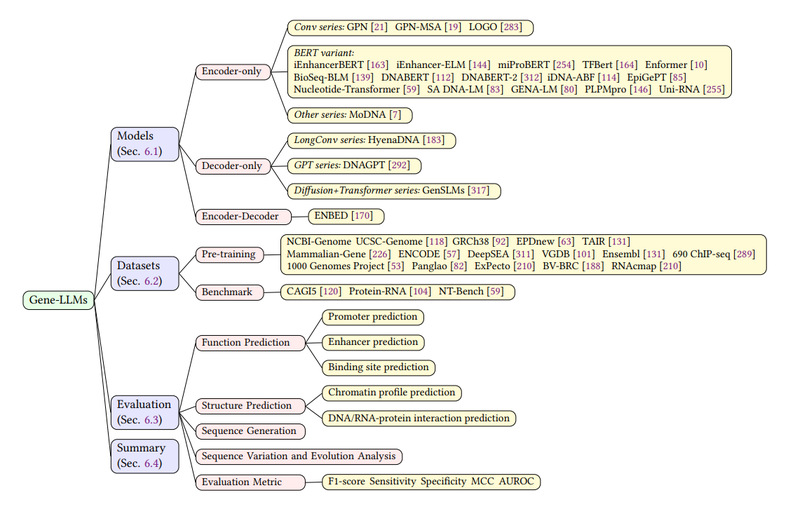
基因组大语言模型侧重于基因组数据,训练其理解和预测遗传学和基因组学的各个方面,可用于分析DNA序列,了解基因变异,协助基因研究工作,如确定疾病的基因标记或了解生物进化等。
多模态科学大语言模型
多模态科学大语言模型是最先进的多功能模型,能够处理和整合多种类型的科学数据。它们可以处理文本、分子、蛋白质等,适用于跨越不同数据类型的复杂科学研究。它是多拟态科学大语言模型是跨学科研究领域的无价之宝,可以综合来自不同科学领域的知识,提供全面的解读和见解,推动交叉领域合作。
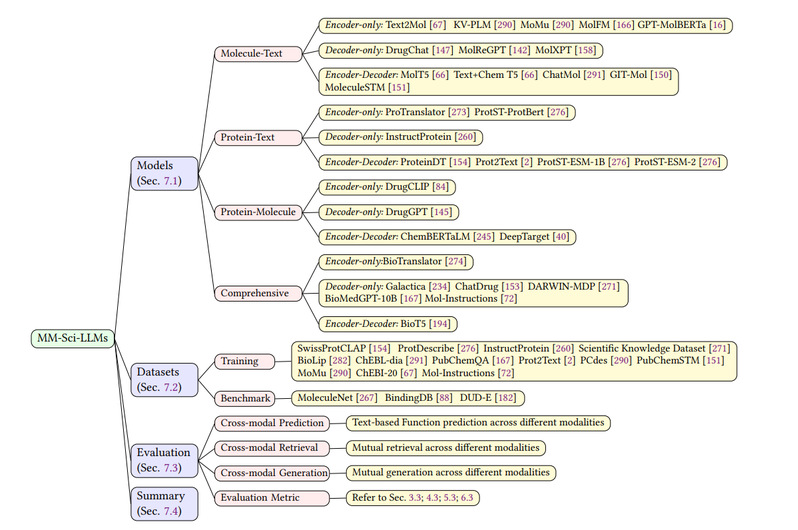
“目前,科学大语言模型的研究中还存在挑战,诸如模型训练数据不充分、模型语义信息捕捉生成不成熟、处理敏感生物数据时会遇到的伦理问题等。我们的综述为人工智能和生命科学、物质科学等交叉领域提供全面的资源,为推动“人工智能助力科学”(AI for Science)的发展提供了新思路。”张强研究员说。
未来,团队还希望构建更大规模、高质量和跨模态的训练数据集,将3D结构和时间信息集成到基于语言的建模方法中,同时不断探索 Sci-LLMs 与外部知识的协同作用,利用工具增强 Sci-LLMs并开发出对应的评估工具和基准,最终实现 Sci-LLMs 和人类价值观的超级对齐(Super-alignment),更好地为科学研究服务。
生物与分子智造研究院AI交叉中心团队
浙江大学杭州国际科创中心生物与分子智造研究院 AI 交叉中心团队致力于大型语言模型和知识图谱等新兴通用人工智能技术在合成生物、分子材料、生命健康等领域的应用研究。近年来与多学科团队合作开展AI科学交叉研究,先后提出化学元素知识图谱 ElementKG、基于“知识增强+提示学习”的分子图对比学习 KANO、知识增强的蛋白质预训练模型 OntoProtein、多层次提示增强的蛋白质预训练模型 PromptProtein、基于知识指令的文本-蛋白质跨模态大模型 InstructProtein、面向单细胞转录组学数据分析的图神经网络模型 scDeepSort、细胞通信知识图谱关联推断模型 SPATalk 等等。近两年在 Nature Machine Intelligence、Nature Communications 等发表多篇 Nature 子刊论文,以及在 NeurIPS、ICML、ICLR、AAAI、IJCAI 等人工智能顶会发表多篇 AI for Science 研究论文。


