在化学领域,逆合成分析是化学合成和分子材料研发的关键步骤。但逆合成预测是一对多的问题,即合成目标分子可能存在多个反应方法。如何将“科研砖工们”从繁复、低效的实验中解放出来,真正找到准确、有效的合成路径?人工智能正在加速这一过程。
图片来源:微信表情包“生物实验室的日常”
近日,我院AI交叉中心陈华钧教授和张强研究员团队原创基于迭代字符串编辑模型(EditRetro)的逆合成预测方法。通过生成式Transformer架构,将单步逆合成预测重新定义为分子字符串编辑任务,利用显式的序列编辑操作迭代地优化目标分子字符串,从而生成前体化合物。相关成果发表在Nature Communications。

论文的第一作者为浙江大学杭州国际科创中心生物与分子智造研究院博士后韩玉强,通讯作者为浙江大学计算机科学与技术学院的陈华钧教授、科创中心生物与分子智造研究院的张强研究员和药学院的侯廷军教授。

EditRetro
打通逆合成预测的“快速通道”
分子合成需要经过一系列的化学反应,比如A+B->C+D。“逆合成分析是通过将目标分子递归分解为更简单的前体分子,从而设计目标化合物的合成路线。也就是要获得C化合物,就要找到A+B这条反应路径。”张强解释道。
问题是,逆合成预测存在很大的可疑合成路径空间。在海量数据中找到正确解,人工智能或许比人类更有办法。
团队开发的模型EditRetro通过引入基于编辑的生成模型,使用显式的字符串序列编辑操作,重新定义了逆合成预测问题。张强介绍道:“该方法包含三个主要编辑操作:序列重定位、占位符插入和符号插入。也就是在序列中找到某一位置,放入占位符,在保持反应总原子数不变的同时,经过对各字符串中原子的增加、删除、替换和多次排列组合,有效地生成高质量且多样的前体化合物。”
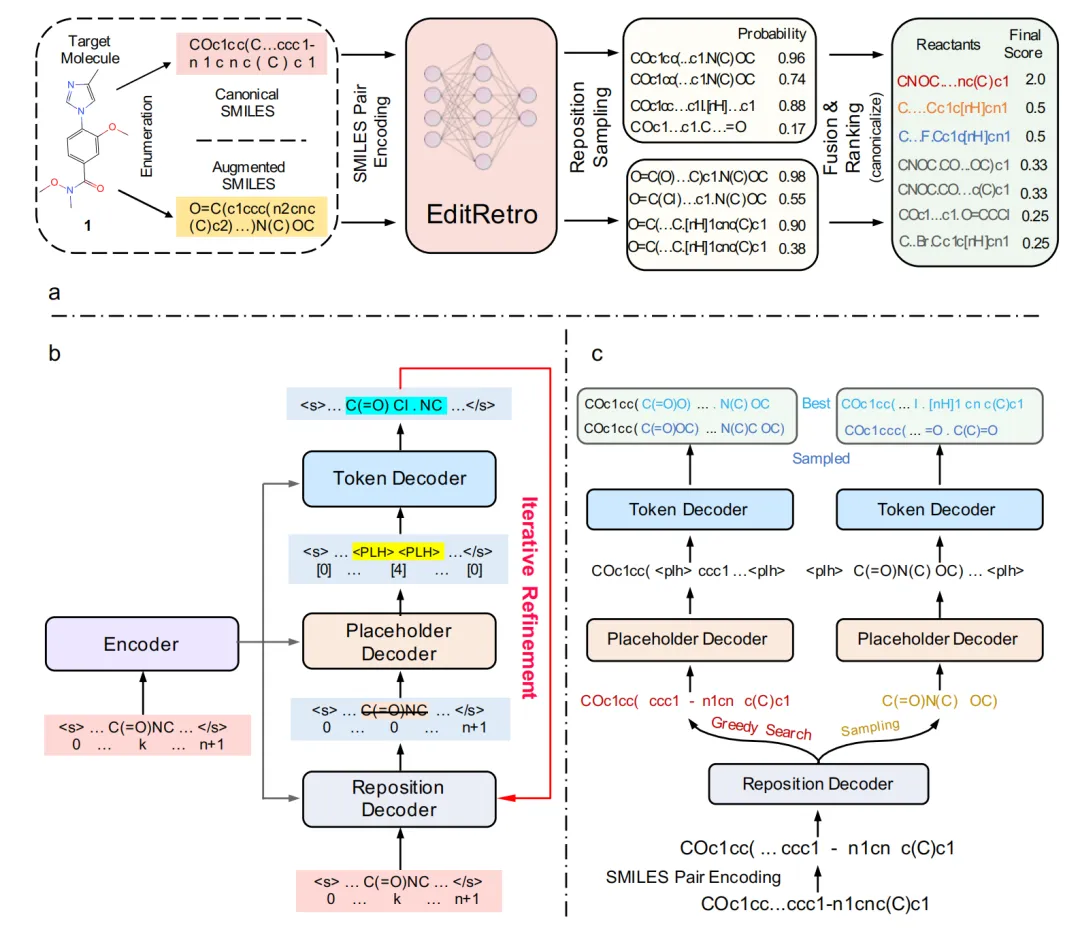
图:团队所提出的EditRetro方法的示意图。
在模型推理阶段,研究团队设计了重定位采样和序列增强模块,以提高预测的准确性和多样性。序列增强模块随机选择分子图枚举的起始原子和方向,创建从产物字符串到反应物的多样化编辑路径。重定位采样模块则通过采样序列重定位分类器的输出,识别更广泛的反应类型。
快速准确,或可提高分子材料的生产效率
团队在基准数据集USPTO-50K上的广泛实验表明,该模型生成的结果具有高质量和多样性,达到了60.8%的top-1准确率和80.6%的top-3准确率。此外,在样本量100万的USPTO-FULL数据集上,该方法同样表现出色,进一步验证了其在处理多样化反应类型方面的优势。
张强表示:“这些研究结果表明,基于编辑的逆合成预测模型在处理复杂化学反应方面有着显著优势,能够为化学家和研究人员提供一个高效且准确的工具,极大地加速分子材料的开发和有机合成的进程。”
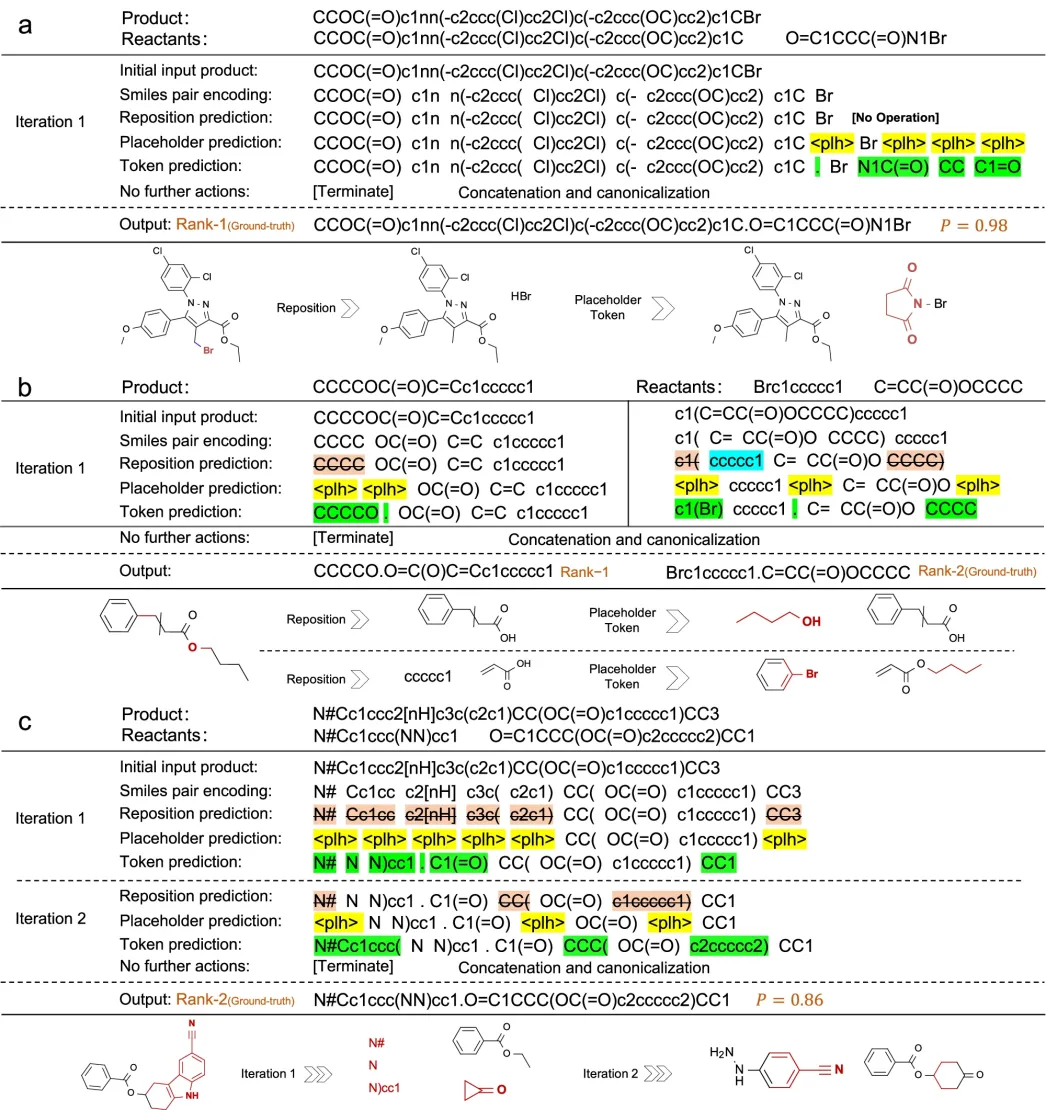
图:EditRetro的逆合成推理过程
逆合成预测对于化学合成路径设计至关重要,团队原创的EditRetro模型在处理复杂化学反应上的优势,包括手性、开环和成环反应等。“所有的分子都需要合成出来,这项技术有望应用于更广泛的化学合成规划中,推动药物开发、材料科学等领域的快速发展” 张强说道。未来,团队将继续深入研究这一领域,探索更多创新的逆合成预测方法,推动人工智能在化学合成中的应用。
https://www.nature.com/articles/s41467-024-50617-1
团队简介
浙江大学杭州国际科创中心生物与分子智造研究院AI交叉中心团队致力于大型语言模型和知识图谱等新兴通用人工智能技术在合成生物、分子材料、生命健康等领域的应用研究。近年来与多学科团队合作开展AI科学交叉研究,在Nature Machine Intelligence、Nature Communications等发表多篇Nature子刊论文,以及在NeurIPS、ICML、ICLR、AAAI、IJCAI等国际人工智能顶级会议发表多篇AI for Science研究论文。
团队主页:http://scimind.ai/about-us


